Troubleshooting Oracle Database encoding issues
Introduction
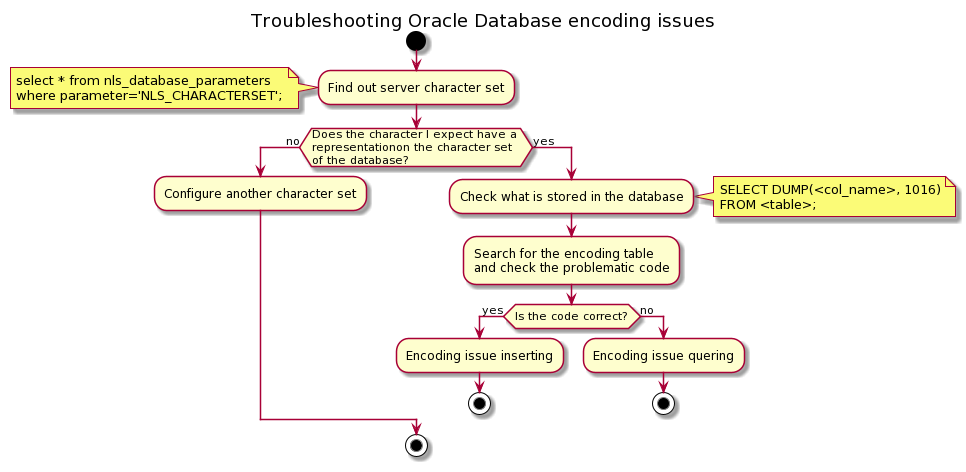
You get strange characters from a database query. Let’s understand how server and client work together so that we can troubleshoot and fix encoding issues.
How does Oracle store text internally
Text characters, like we see them on a screen or printed on paper, are visual representations. We see an “a” or a comma, but Oracle has to turn these characters into numbers to store them as binary data (with zeros and ones). This conversion uses character encoding tables1. Character encoding tables are a system to map between characters (those with a visual representation and other none printable ones) and a number. The same happens when we store text in a regular plain text file.
The first important thing to know is which character encoding table, or character set, uses our Oracle Database instance. To find out, we can run this query:
select * from nls_database_parameters
where parameter='NLS_CHARACTERSET';
We analyse two results on different database instances.
Example 1 (database with ISO 8859-1 encoding)
| PARAMETER | VALUE |
|---|---|
| NLS_CHARACTERSET | WE8ISO8859P1 |
In this case, we get WE8ISO8859P1. If we search in Google the WE8ISO8859P1 character set, we come to a page like https://docs.oracle.com/cd/A57673_01/DOC/server/doc/SRF73/ch4.htm, with a list of encodings used by Oracle or https://docs.oracle.com/cd/B19306_01/server.102/b14225/ch2charset.htm#g1009784, where they explain the way of naming. Anyway, we find out that they mean ISO 8859-1.
We can face one type of problem: we might need to store characters with no mapping in a particular character set. For instance, in ISO 8859-1, we cannot represent the character € (EURO). If we need to, we have to change the character set of our database instance.
Example 2 (database with AL32UTF8 encoding)
| PARAMETER | VALUE |
|---|---|
| NLS_CHARACTERSET | AL32UTF8 |
To avoid problems like the one described above, we could use the character set AL32UTF8, supporting most languages in the world2.
Character set conversion
The next point is to understand what happens if the client (the one who inserts or query data from the database) uses a different character set.
An environment variable, NLS_LANG, tells the Oracle software what character set the client is using. It can be the same as the server, but it doesn’t have to be the same.
On newer versions (8.0.4 onwards), the conversion happens at the client side3. Conversion means that the client knows which character set the database needs and does the conversion, if necessary. On older versions, this conversion happened on the server side.
It’s important to realise that an error could occur when inserting data into the database and querying them. We’ll see in the following section how to troubleshoot.
Troubleshooting
We’ve seen three types of issues:
- Database configuration: the character set configured in the database has no mapping for a particular character. For instance, ISO 8859-1 has no representation for the € (EURO) sign.
- Conversion error during insert.
- Conversion error during query.
Find out what’s in the database
This query will help us with the troubleshooting:
SELECT DUMP(<col_name>, 1016) FROM <table>;
- <col_name> and <table> are the name of the column and the table where our is stored.
DUMP(<column\_name> , 1016)is a function that will return:- Character set used by the server.
- Hexadecimal code for every character in the string.
1016 is 16 (hexadecimal code) + 1000 (asks Oracle to return database character set).
Example where a character has no representation in the database character set
We get back from a query 12 ? instead of 12 €. We run the query above and we obtain:
Typ=1 Len=4 CharacterSet=SE8ISO8859P3: 31,32,20,3f
There is useful information:
- Server uses SE8ISO8859P3 encoding (ISO 8859-3)
- There are 4 characters stored with the following hexadecimal codes:
- 31
- 32
- 20
- 3f
What happened here is that when we tried to insert 12 €, there was no code available in ISO 8859-3 for the € sign. It’s not possible to store it in this database instance with this configuration. Therefore, Oracle inserted the 3f code (question mark)4
Example where a conversion error occurs
If the character we are troubleshooting does have a representation in the character set used by the database server, we need to find out whether the correct code is in the database server or not:
- It’s the correct one: the problem is at querying time.
- Wrong code is in the database: the problem happened already during insertion.
In this example, we expect the text ¡hola! but we get ?hola!. We want to see what is stored in the database. We execute SELECT DUMP(<col_name>, 1016) FROM <table>; (substitute <column_name> and <table_name> by yours). We get:
Typ=1 Len=4 CharacterSet=AL32UTF8: 3f,68,6f,6c,61,21
We go to UTF-8 definition5 and see that 3f means the question mark sign (?). That’s not what we expect that to be: The error is on the application or the client that inserted that value.
Otherwise, if we had obtained:
Typ=1 Len=4 CharacterSet=AL32UTF8: c2,a1,68,6f,6c,61,21
We would see that c2 a1 means “Inverted exclamation mark”. In this case, the correct codes are in the database, and we would know that the problem is on the application or the client querying the data (or processing afterwards).
More information about NLS_LANG
This page is handy if you want to deepen into how Oracle Database handles encoding: https://www.oracle.com/database/technologies/faq-nls-lang.html
Summary
We reviewed some text encoding aspects of an Oracle Database. We learned how to troubleshoot encoding issues (we see strange characters on our application or a database query).